Imagine you’re writing a program that does one of the following:
Dubious claim. Let me give an example. It’s almost certain your system measures percentiles of some primitive operation (e.g. ) and it’s possible your system measures percentiles of some aggregate operation (e.g. ). This post is about napkin-math’ing timing of aggregate operations using only metrics about the primitive.
These operations depend on the timing of the first, third, and last of calls respectively. Estimating the timings of operations like these can be challenging when observability systems are built only to measure the performance of single operations. However, if we can assume that response times from $ are independent, we can compose an estimate of the timing of the of calls with order statistics.
The order statistics of a random sample are the sample values placed in ascending order. We denote the minimum value from this sample as , the second smallest as , and so forth (i.e. ). Given the CDF () for a single call, the CDF of the order statistic of calls is given as:
In some cases we can further simplify an estimate. For example, we can show that the of exponential random variables with parameter is exponentially distributed with parameter .
In each term of the CDF we calculate the probability that values are smaller and values are larger than . When using or , we have easier to calculate special cases:
Reframe our Base CDF. Replace with s.t. .
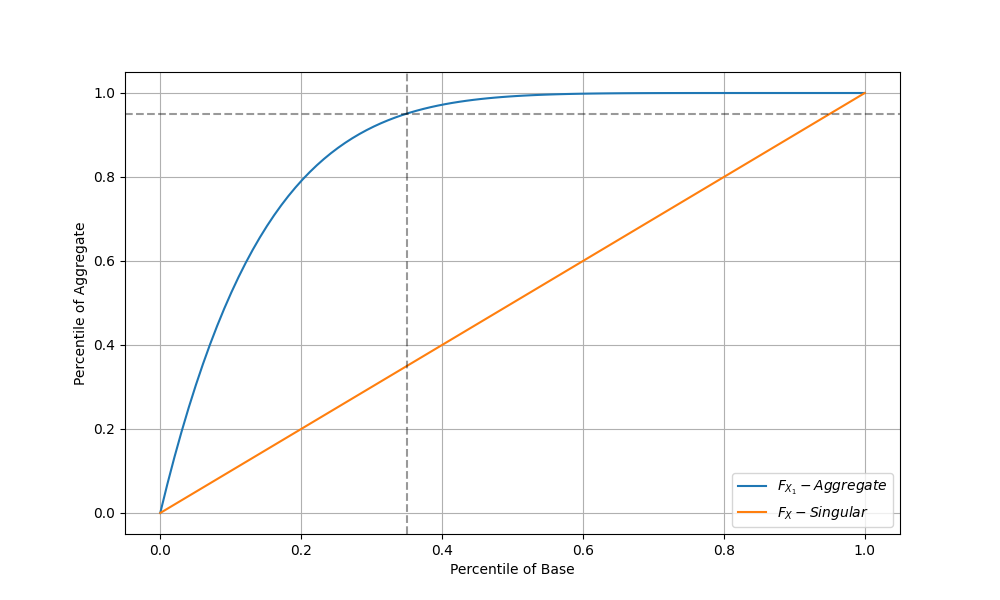
However, we don’t often have closed-form distributions for responses from $. Luckily we don’t need them to provide good estimates. Rather than working with a base CDF () that maps response times (in ms) to a percentile (on the unit interval), imagine that our base CDF maps a percentile to itself. Unlike distributions, percentiles of response times are readily available in our observability system.
We can also take the inverse of to make more intuitive statements, e.g. “pXX of the aggregate is pYY of the base”, but we don’t need to belabor this point.
Under this reframing, indicates that the percentile of the singular call maps to the percentile of the aggregate distribution. Consider an example using the response from 7 nodes. The p95 of our aggregate call roughly corresponds to the p35 of the base distribution.
This “trick” is a general property and can be used without involving any parametric distribution of response times. If we wanted to be (slightly) more formal we could take to get the p95 of this aggregate call, but in most cases a quick glance at the metrics of the base distribution will suffice.